rm(list = ls())
library(tidyverse)
library(brms)
library(here) #For finding root directory
source( here("R","simulate_data_no_underscores.R") ) #Load my needed custom function
source( here("R","psychometric_function.R") ) #Load my needed custom function
set.seed(989) #ensures reproducibility for testing
break_brms_by_making_numTargets_numeric<- FALSE #Change factor to numeric, right before doing formula fit, so
#I know that it's brms that's the problem rather than the rest of my codelogSigma estimation seems biased high
Typically brms estimates logSigma as -1.41 instead of true value of -1.67.
Will generate fake data that includes differences between participants, but doesn’t model them.
To get started, we load the required packages.
Create simulated trials
Set up simulated experiment design.
Maybe make sure the reference group (that the Intercept estimate pertains to) is the expected-worse group. This is in case I later set priors on the coefficients, so that I can set the priors to all be positive to be less confusing.
Supposedly the levels order determines what brms sets the reference group to.
numTargetsConds<- factor( c("three", "two"),
levels=c("three", "two") ) #This defines factor order. Worst is first.
numSubjects<- 25
trialsPerCondition<- 30#20
laboratories<- factor( c("Holcombe", "Roudaia"),
levels=c("Holcombe", "Roudaia") ) #This defines the factor order
#Array of speeds (not very realistic because mostly controlled by a staircase in actual experiment)
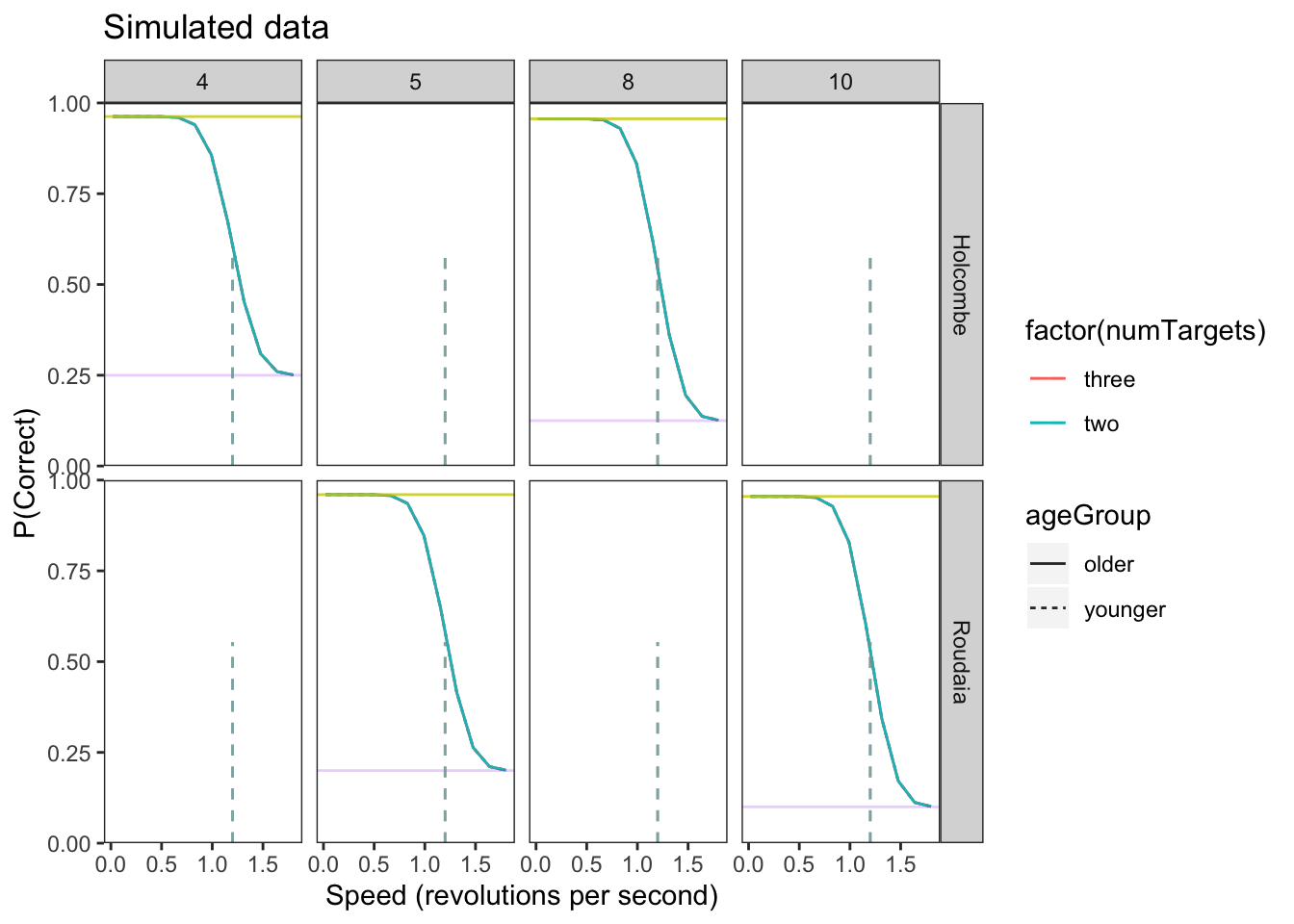
speeds<-seq(.02,1.8, length.out = 12) # trials at 12 different speeds between .02 and 1.8In order to build and test our model in brms, we must first create a simulated data set that is similar to our actual experiment data. This allows us to confirm the brms model is working and successfully recovers the parameters we set before applying it to our real experimental data that has unknown parameter values. In the actual data, there will be many group-wise differences in location and scale parameters. The following simulated data only has explicit differences between the \(\eta\) (location) of the two age groups (older vs younger).
Values per factor
# A tibble: 8 × 2
name value
<chr> <int>
1 lab 2
2 gender 2
3 ageGroup 2
4 subjWithinGroup 25
5 numTargets 2
6 obj_per_ring 4
7 speed 12
8 trialThisCond 30Create between-subject variability within each group, to create a potential multilevel modeling advantage. Can do this by passing the participant number to the location-parameter calculating function. Because that function will be called over and over, separately, the location parameter needs to be a deterministic function of the participant number. So it needs to calculate a hash or something to determine the location parameter. E.g. it could calculate the remainder, but then the location parameters wouldn’t be centered on the intended value for that condition. To do that, I think I need to know the number of participants in the condition, n, and number them 1..n. Then I can give e.g. participant 1 the extreme value on one side of the condition-determined value and give participant n the extreme value on the other side. So I number participants separately even within age*gender to maintain the age and gender penalties, but not within speed, of course. Also not within targetLoad or obj_per_ring.
Because the present purpose of numbering participants is to inject the right amount of between-participant variability, I will number the participants with a range of numbers that has unit standard deviation. Will call this column “subjStandardized”.
Choose values for psychometric function for younger and older
lapse <- 0.05
sigma <- 0.2
location_param_base<-1.2 #location_param_young_123targets <- c(1.7,1.0,0.8)
one_less_target_benefit<-0 #0.3 #penalty for additional target
youth_benefit <- 0 #0.4 #Old people have worse limit by this much
male_benefit <-0 #0.15 #Female worse by this much
Roudaia_lab_benefit <- 0 #0.2
#Set parameters for differences between Ss in a group
eta_between_subject_sd <- 0 #0.1
#Using above parameters, need function to calculate a participant's location parameter
#Include optional between_subject_variance
location_param_calculate<- function(numTargets,ageGroup,gender,lab,
subjStandardized,eta_between_subject_sd) {
base_location_param <- location_param_base# location_param_young_123targets[targetLoad]
#calculate offset for this participant based on desired sigma_between_participant_variance
location_param <- base_location_param +
subjStandardized * eta_between_subject_sd
after_penalties <-location_param +
if_else(lab=="Roudaia",1,0) * Roudaia_lab_benefit +
if_else(ageGroup=="younger",1,0) * youth_benefit +
if_else(numTargets=="two",1,0) * one_less_target_benefit +
if_else(gender=="M",1,0) * male_benefit
return (after_penalties)
}
#Need version with fixed eta_between_subject_sd for use in mutate
location_param_calc_for_mutate<- function(numTargets,ageGroup,gender,lab,
subjStandardized) {
location_param_calculate(numTargets,ageGroup,gender,lab,
subjStandardized, eta_between_subject_sd)
}Using the psychometric function, simulate whether participant is correct on each trial or not, and add that to the simulated data.
Plot data
upper_bound = 1 - L*(1-C)
Setting up our Model in brms
Setting a model formula in brms allows the use of multilevel models, where there is a hierarchical structure in the data. But at this point we haven’t made the model multi-level as we have been concentrating on the basics of brms.
The bf() function of brms allows the specification of a formula. The parameter can be defined by population effects, where the parameter’s effect is fixed, or group level effects where the parameter varies with a variable such as age. The “family” argument is a description of the response distribution and link function that the model uses. For more detailed information on setting up a formula and the different arguments in BRMS seehttps://paulbuerkner.com/brms/reference/brmsformula.html
The model we used is based off our psychometric function used to generate the data mentioned previously. The only explicitly-coded difference in our simulated data is in the location parameter of older vs younger. Thus, in addition to the psychometric function, we allowed \(\eta\) and \(\log(\sigma)\) to vary by age group in the model. Because the psychometric function doesn’t map onto a canonical link function, we use the non-linear estimation capability of brms rather than linear regression with a link function.
Alex’s note: Using the nonlinear option is also what allowed us to set a prior on the thresholds \(\eta\), because we could then parametrize the function in terms of the x-intercept, whereas with the link-function approach, we are stuck with the conventional parameterization of a line, which has a term for the y-intercept but not the x-intercept
my_formula <- brms::bf(
correct ~ chance_rate + (1-chance_rate - lapseRate*(1-chance_rate)) * Phi(-(speed-eta)/exp(logSigma))
)
my_formula <- my_formula$formula
#If don't want to fit lapseRate, need to supply it
#data_simulated$lapseRate<- lapse
#If I don't want to fit eta, need to supply it
true_eta<- location_param_base
data_simulated$eta<- true_eta
my_brms_formula <- brms::bf(
correct ~ chance_rate + (1-chance_rate - lapseRate * (1-chance_rate))*Phi(-(speed-eta)/exp(logSigma)),
#eta ~ 1, #lab + ageGroup + numTargets + gender,
lapseRate ~ 1, #~1 estimates intercept only
logSigma ~ 1,#ageGroup,
family = bernoulli(link="identity"), #Otherwise the default link 'logit' would be applied
nl = TRUE #non-linear model
)Set priors
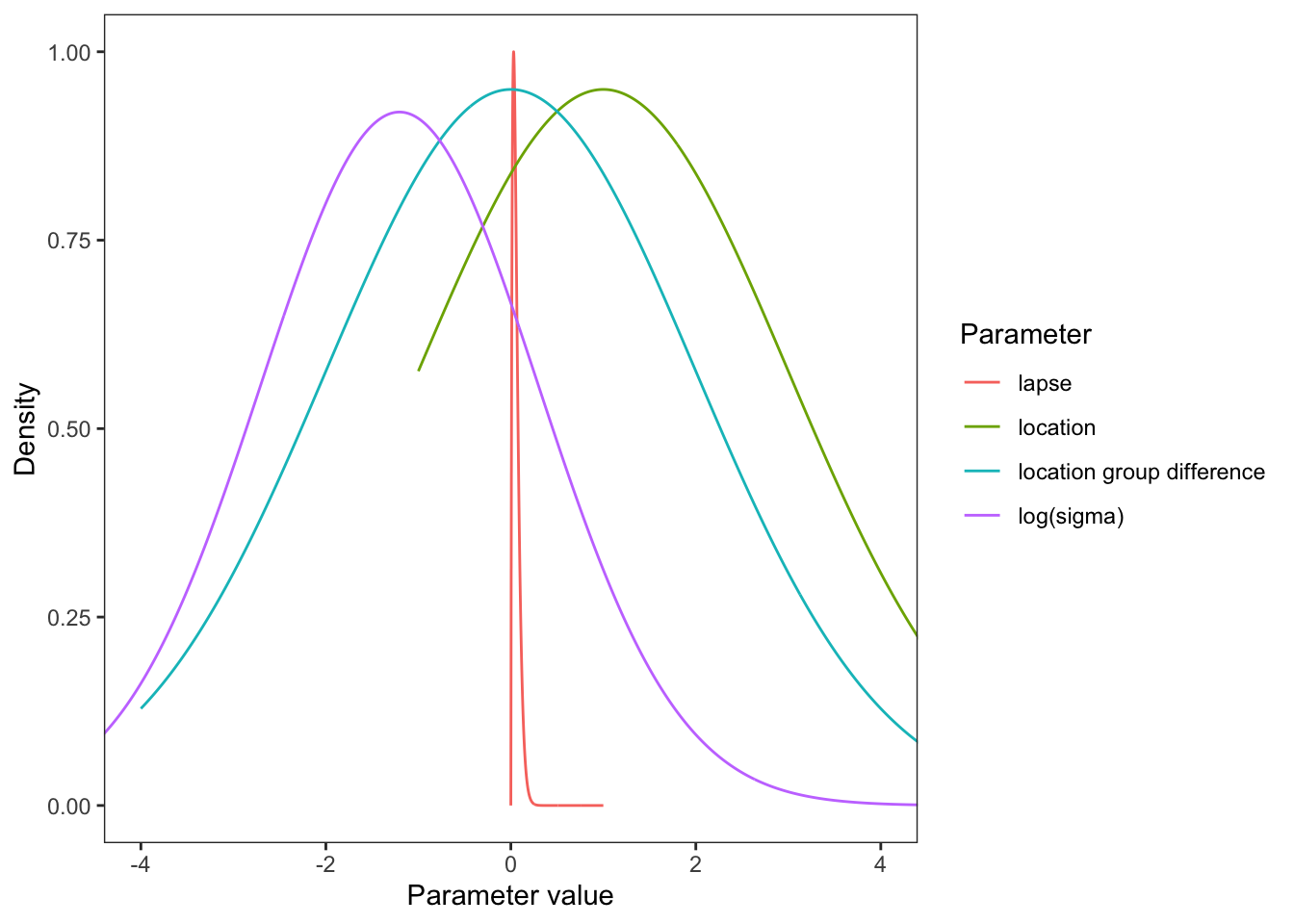
See visualize_and_select_priors.html for motivation.
Plot the priors
Fitting Model to Simulated Data
Fitting the model gives an estimation of the average parameter value of the participants. The brm() function is used to fit the model based on the given formula, data and priors. Other arguments of brm can adjust the model fitting in various ways, for more information on each of the arguments see https://paulbuerkner.com/brms/reference/brm.html
if (break_brms_by_making_numTargets_numeric) {
#Make numeric version of numTargets
data_simulated <- data_simulated |>
mutate(targets = case_when(
numTargets == "two" ~ 2,
numTargets == "three" ~ 3,
TRUE ~ 0
))
#Delete old column
data_simulated$numTargets <- NULL #delete column
data_simulated <- data_simulated %>%
rename(numTargets = targets)
}[1] "Show stan code . But I dont know how to interrogate it to see the factors."// generated with brms 2.22.0
functions {
}
data {
int<lower=1> N; // total number of observations
array[N] int Y; // response variable
int<lower=1> K_lapseRate; // number of population-level effects
matrix[N, K_lapseRate] X_lapseRate; // population-level design matrix
int<lower=1> K_logSigma; // number of population-level effects
matrix[N, K_logSigma] X_logSigma; // population-level design matrix
// covariates for non-linear functions
vector[N] C_1;
vector[N] C_2;
vector[N] C_3;
int prior_only; // should the likelihood be ignored?
}
transformed data {
}
parameters {
vector<lower=0,upper=1>[K_lapseRate] b_lapseRate; // regression coefficients
vector<lower=-2,upper=1.6>[K_logSigma] b_logSigma; // regression coefficients
}
transformed parameters {
real lprior = 0; // prior contributions to the log posterior
lprior += beta_lpdf(b_lapseRate | 2, 33.33);
lprior += normal_lpdf(b_logSigma | -1.20397280432594, 1.5)
- 1 * log_diff_exp(normal_lcdf(1.6 | -1.20397280432594, 1.5), normal_lcdf(-2 | -1.20397280432594, 1.5));
}
model {
// likelihood including constants
if (!prior_only) {
// initialize linear predictor term
vector[N] nlp_lapseRate = rep_vector(0.0, N);
// initialize linear predictor term
vector[N] nlp_logSigma = rep_vector(0.0, N);
// initialize non-linear predictor term
vector[N] mu;
nlp_lapseRate += X_lapseRate * b_lapseRate;
nlp_logSigma += X_logSigma * b_logSigma;
for (n in 1:N) {
// compute non-linear predictor values
mu[n] = (C_1[n] + (1 - C_1[n] - nlp_lapseRate[n] * (1 - C_1[n])) * Phi( - (C_2[n] - C_3[n]) / exp(nlp_logSigma[n])));
}
target += bernoulli_lpmf(Y | mu);
}
// priors including constants
target += lprior;
}
generated quantities {
}Compiling Stan program...Trying to compile a simple C fileRunning /Library/Frameworks/R.framework/Resources/bin/R CMD SHLIB foo.c
using C compiler: ‘Apple clang version 16.0.0 (clang-1600.0.26.6)’
using SDK: ‘’
clang -arch arm64 -I"/Library/Frameworks/R.framework/Resources/include" -DNDEBUG -I"/Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/library/Rcpp/include/" -I"/Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/library/RcppEigen/include/" -I"/Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/library/RcppEigen/include/unsupported" -I"/Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/library/BH/include" -I"/Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/library/StanHeaders/include/src/" -I"/Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/library/StanHeaders/include/" -I"/Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/library/RcppParallel/include/" -I"/Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/library/rstan/include" -DEIGEN_NO_DEBUG -DBOOST_DISABLE_ASSERTS -DBOOST_PENDING_INTEGER_LOG2_HPP -DSTAN_THREADS -DUSE_STANC3 -DSTRICT_R_HEADERS -DBOOST_PHOENIX_NO_VARIADIC_EXPRESSION -D_HAS_AUTO_PTR_ETC=0 -include '/Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/library/StanHeaders/include/stan/math/prim/fun/Eigen.hpp' -D_REENTRANT -DRCPP_PARALLEL_USE_TBB=1 -I/opt/R/arm64/include -fPIC -falign-functions=64 -Wall -g -O2 -c foo.c -o foo.o
In file included from <built-in>:1:
In file included from /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/library/StanHeaders/include/stan/math/prim/fun/Eigen.hpp:22:
In file included from /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/library/RcppEigen/include/Eigen/Dense:1:
In file included from /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/library/RcppEigen/include/Eigen/Core:19:
/Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/library/RcppEigen/include/Eigen/src/Core/util/Macros.h:679:10: fatal error: 'cmath' file not found
679 | #include <cmath>
| ^~~~~~~
1 error generated.
make: *** [foo.o] Error 1Start samplingTime taken (min) = 2.7non_model' NOW (CHAIN 1).
Chain 2:
Chain 2: Gradient evaluation took 0.048928 seconds
Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 489.28 seconds.
Chain 2: Adjust your expectations accordingly!
Chain 2:
Chain 2:
Chain 1:
Chain 1: Gradient evaluation took 0.05062 seconds
Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 506.2 seconds.
Chain 1: Adjust your expectations accordingly!
Chain 1:
Chain 1:
Chain 2: Iteration: 1 / 700 [ 0%] (Warmup)
Chain 1: Iteration: 1 / 700 [ 0%] (Warmup)
Chain 2: Iteration: 70 / 700 [ 10%] (Warmup)
Chain 1: Iteration: 70 / 700 [ 10%] (Warmup)
Chain 2: Iteration: 140 / 700 [ 20%] (Warmup)
Chain 1: Iteration: 140 / 700 [ 20%] (Warmup)
Chain 2: Iteration: 210 / 700 [ 30%] (Warmup)
Chain 1: Iteration: 210 / 700 [ 30%] (Warmup)
Chain 2: Iteration: 280 / 700 [ 40%] (Warmup)
Chain 1: Iteration: 280 / 700 [ 40%] (Warmup)
Chain 1: Iteration: 350 / 700 [ 50%] (Warmup)
Chain 1: Iteration: 351 / 700 [ 50%] (Sampling)
Chain 2: Iteration: 350 / 700 [ 50%] (Warmup)
Chain 2: Iteration: 351 / 700 [ 50%] (Sampling)
Chain 1: Iteration: 420 / 700 [ 60%] (Sampling)
Chain 2: Iteration: 420 / 700 [ 60%] (Sampling)
Chain 1: Iteration: 490 / 700 [ 70%] (Sampling)
Chain 2: Iteration: 490 / 700 [ 70%] (Sampling)
Chain 1: Iteration: 560 / 700 [ 80%] (Sampling)
Chain 2: Iteration: 560 / 700 [ 80%] (Sampling)
Chain 1: Iteration: 630 / 700 [ 90%] (Sampling)
Chain 2: Iteration: 630 / 700 [ 90%] (Sampling)
Chain 1: Iteration: 700 / 700 [100%] (Sampling)
Chain 1:
Chain 1: Elapsed Time: 69.954 seconds (Warm-up)
Chain 1: 56.387 seconds (Sampling)
Chain 1: 126.341 seconds (Total)
Chain 1:
Chain 2: Iteration: 700 / 700 [100%] (Sampling)
Chain 2:
Chain 2: Elapsed Time: 70.98 seconds (Warm-up)
Chain 2: 63.503 seconds (Sampling)
Chain 2: 134.483 seconds (Total)
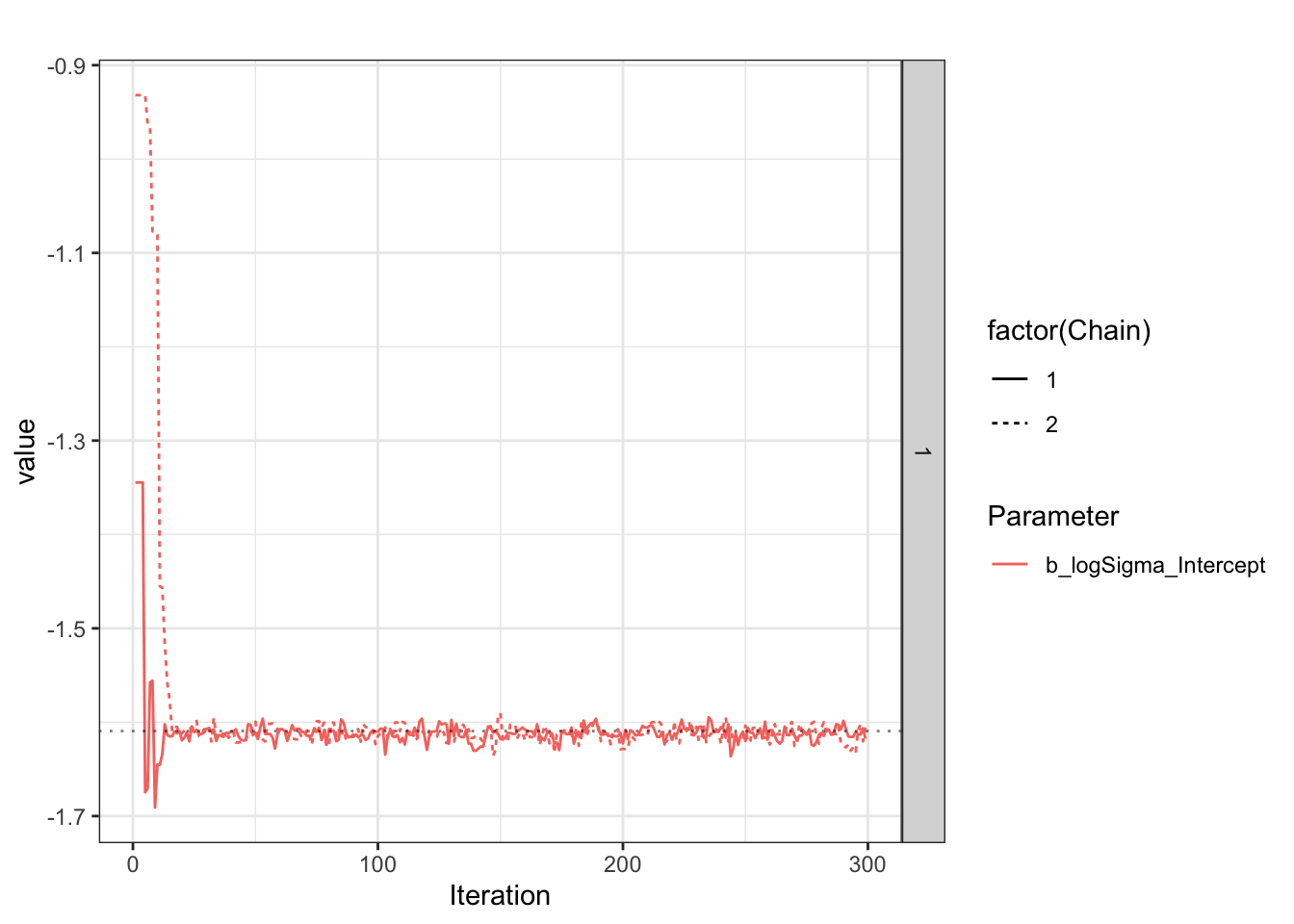
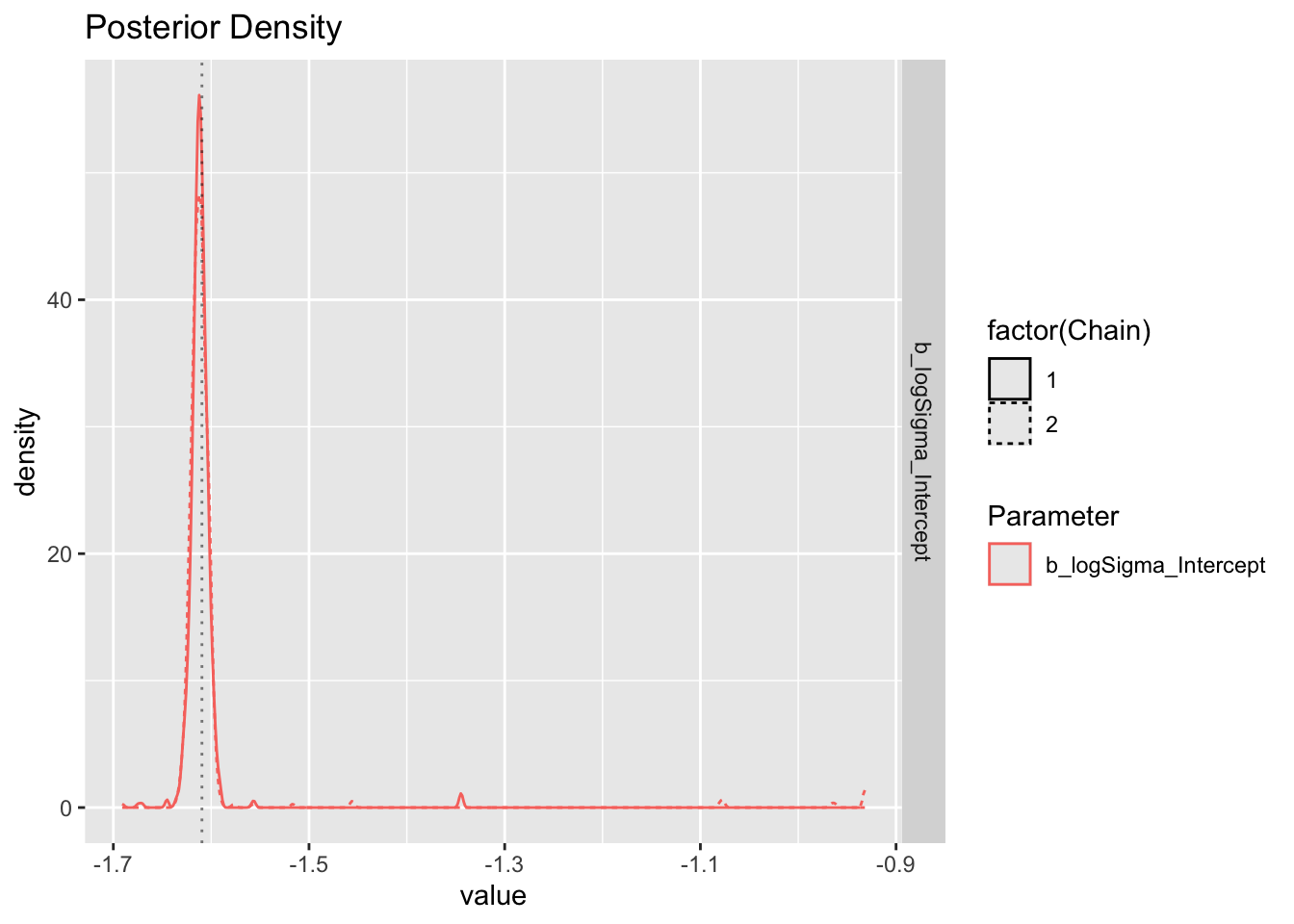
Chain 2: The logSigma estimate tends to have wide confidence intervals, and be biased less negative?
Check how close the fit estimates are to the true parameters.
First report on logSigma.
[1] "Success. Looks like I/brms calculated/estimated the reference group logSigma correctly."Now report on eta_Intercept (if estimated).
If estimating intercept, calculate the reference group location parameter.
Check brms’ estimate of sigma.
[1] "Success. Looks like I/brms calculated/estimated the reference group logSigma correctly."Plot the predictions of the brms fit
For an example condition, model only one factor and only use data relevant to that
Set up all the conditions to calculate the prediction for.
Plot
Adding missing grouping variables: `lab`, `numTargets`, `ageGroup`, `gender`,
`subjWithinGroup`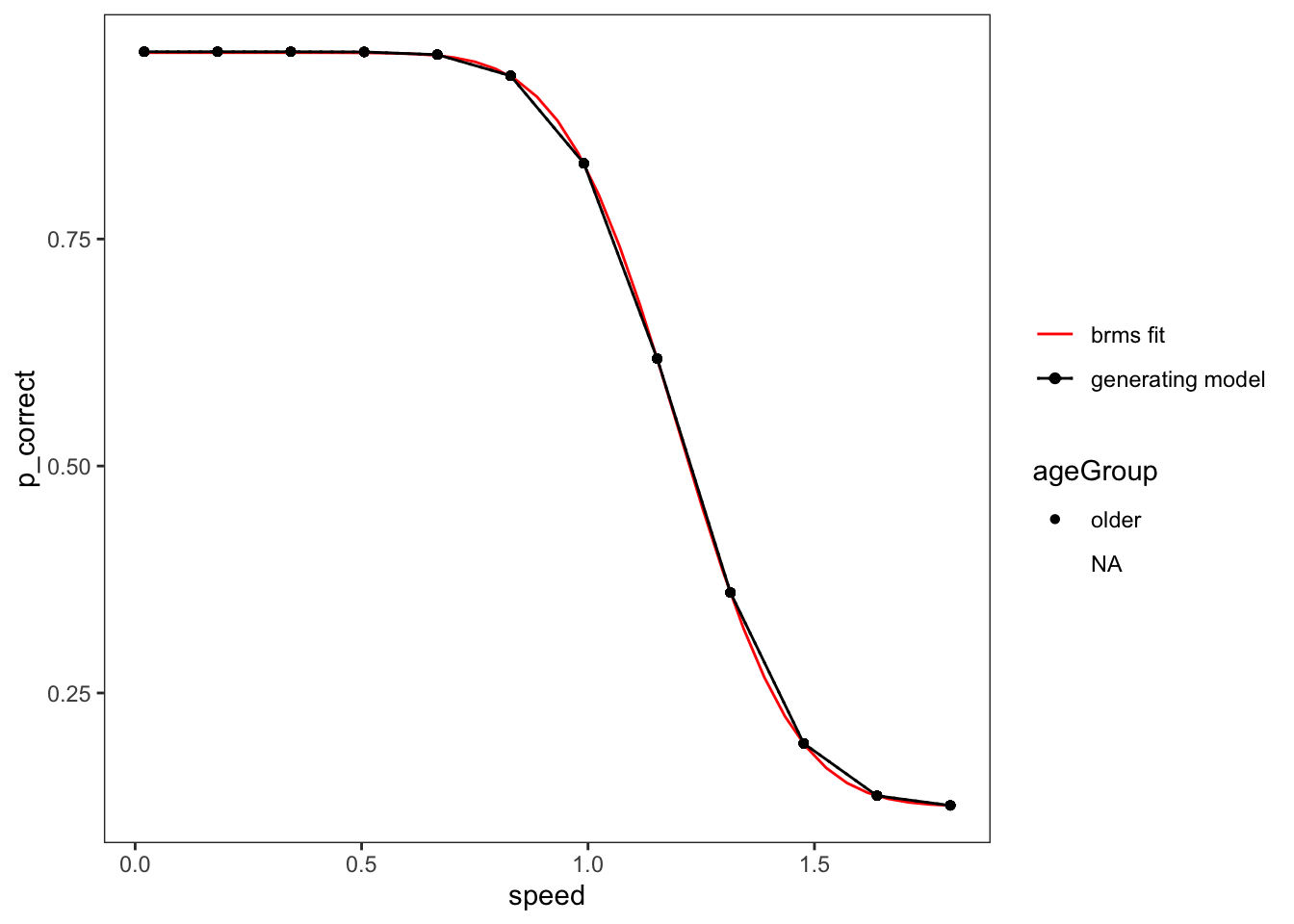
Look at what is happening during the chain, as explained on the Stan forum
Registered S3 method overwritten by 'GGally':
method from
+.gg ggplot2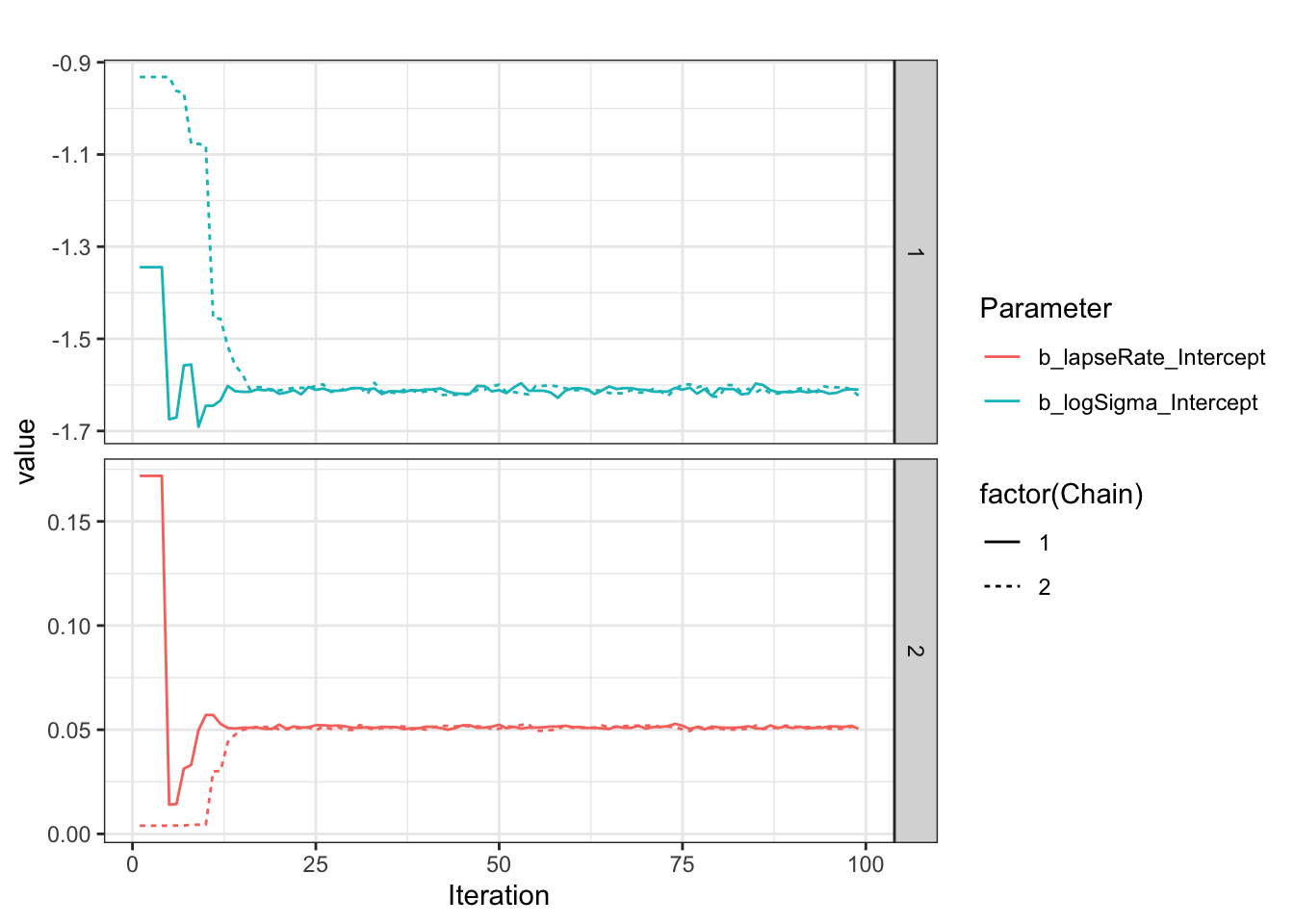
Plot sigma specifically.
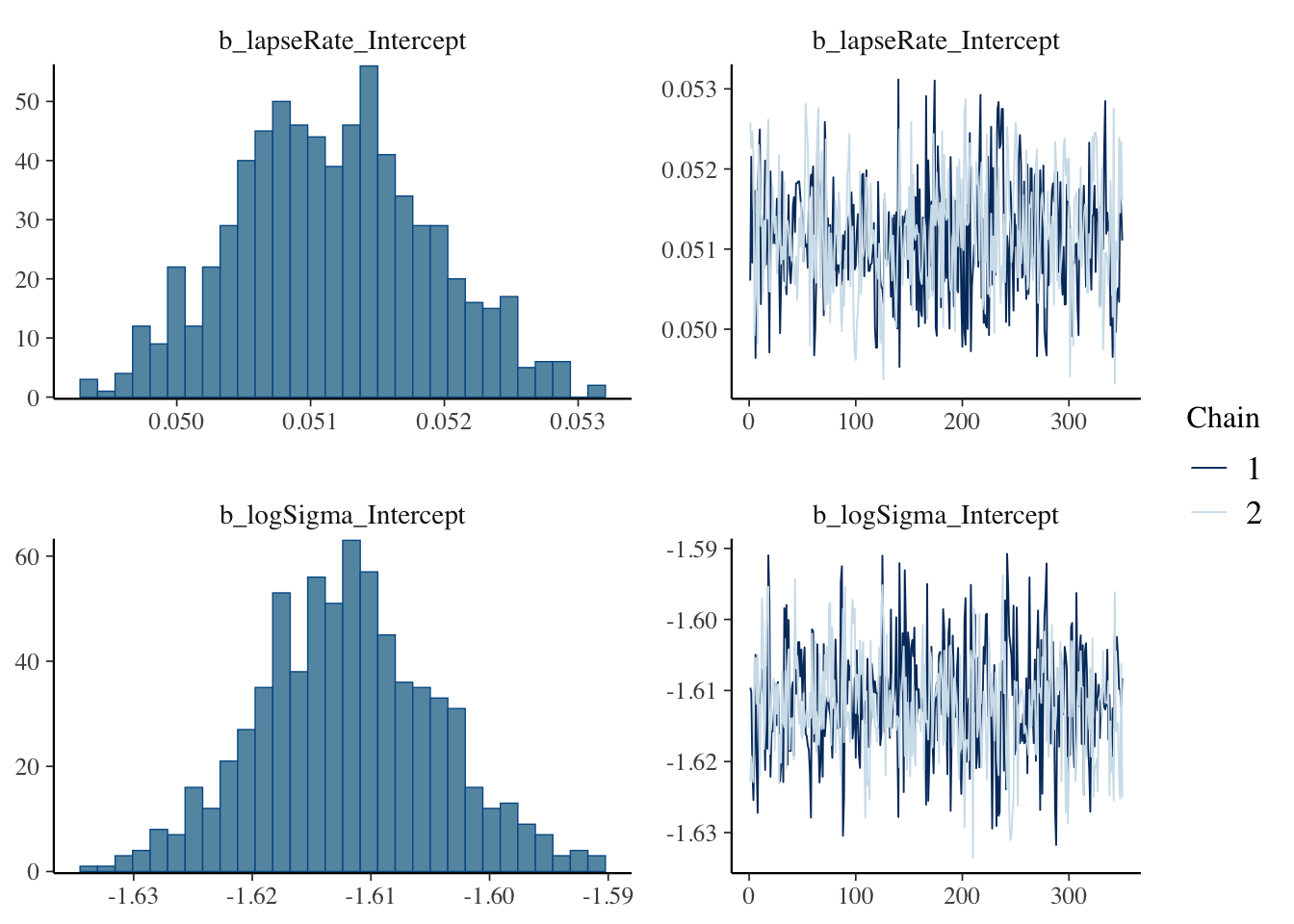
Use brms’ built-in plot to show posterior and chains.
Brms’ conditional_effects method visualizes the model-implied regression curve: